
人工智能和机器学习概述
人工智能应用
人机对战
- AlphaGo
宇宙探索
- Google + NASA
人机对话
- Alexa
- Siri
- Cortana
生活中比较常见
机器视觉
- face++
自然语言处理
- xiaomingbot
- 九歌
智能诊断、推荐系统
- IBM watson
智能交通
- Waymo
机器人和智能控制
人工智能发展概述
起源
人工智能(Artificial Intelligence,简称AI)一词缘于1956年8月美国达特茅斯学院的夏季研讨会。而在1955年8月的时候,“人工智能”在一份关于召开国际人工智能会议的提案中被提出,这份提案由东道主约翰·麦卡锡(John McCarthy)、哈佛大学的马文·明斯基(Marvin Minsky)、IBM的纳撒尼尔·罗切斯特(Nathaniel Rochester)、信息论的创始人克劳德·香农(Claude Shannon)联合递交。一年之后,在达特茅斯召开的第一次人工智能大会,而这次会议被认为是开辟了人工智能研究领域的历史性事件,所以一般来说,它的起源要从1956年算起。
弱人工智能
弱人工智能是指不能真正实现推理和解决问题的智能机器,这些机器表面看像是智能的,但是并不真正拥有智能,也不会有自主意识。
强人工智能
强人工智能是指真正能思维的智能机器,并且认为这样的机器是有知觉的和自我意识的,这类机器可分为
- 类人(机器的思考和推理类似人的思维)
- 非类人(机器产生了和人完全不一样的知觉和意识,使用和人完全不一样的推理方式) 两大类。
强人工智能当前鲜有进展,大部分专家任务至少在未来几十年内难以实现。
图灵测试
1950年,艾伦·图灵提出了著名的图灵测试:如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么称这台机器具有智能。这一简化使得图灵能够令人信服地说明“思考的机器”是可能的。
图灵
艾伦·麦席森·图灵(Alan Mathison Turing,1912年6月23日-1954年6月7日),英国数学家、逻辑学家、密码学家、计算理论家,被称为计算机之父、人工智能之父。图灵提出的著名的图灵机模型为现代计算机的逻辑工作方式奠定了基础。
人工智能发展
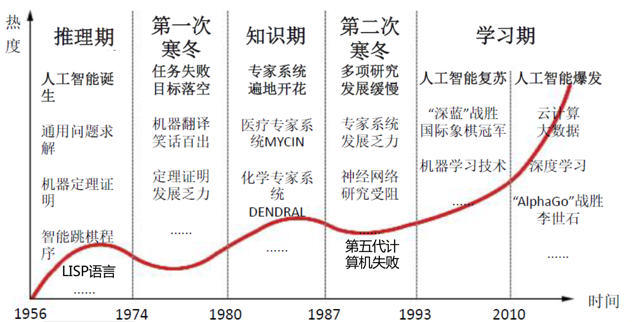
第一次人工智能热潮:主要做的是求解迷宫问题、人机博弈、小游戏、自动定理证明等内容。
第二次人工智能热潮:主要做的是人机对话。它和第一次浪潮中利用推理和搜索等简单规则不同,它仅仅依靠“知识”的支持。
第三次人工智能热潮:第三次人工智能热潮是深度学习和大数据时代。
深度学习
机器学习
区别
人工智能(Artificial Intelligence)就是用机器模拟人的意识和思维。
机器学习(Machine Learning)则是实现人工智能的一种方法,是人工智能的子集。
深度学习(Deep Learning)就是深层次神经网络,是机器学习的一种实现方法,是机器学习的子集。
机器学习
机器学习是人工智能的一个分支,它是实现人工智能的一个核心技术,即以机器学习为手段解决人工智能中的问题。
机器学习是通过一些让计算机可以自动“学习”的算法并从数据中分析获得规律,然后利用规律对新样本进行预测。
- 有监督学习
- 无监督学习
- 半监督学习
- 强化学习
有监督学习
有监督学习(Supervised Learning)指的是事先需要准备好输入与正确输出(区分方法)相配套的训练数据,让计算机进行学习,以便当它被输入某个数据时能够得到正确的输出(区分方法)。
有监督学习需要有大量的训练数据,不仅仅是输入,还需要区分方法,也就是需要正确的数据标签。
无监督学习
无监督学习(Unsupervised Learning)的目的是让计算机自己去学习怎样做一些事情,所有数据只有特征而没有标记。
无监督学习被运用于仅仅提供输入用数据、需要计算机自己找出数据内在结构的场合。其目的是让计算机从数据中抽取其中所包含的模式及规则。
半监督学习
介于有监督学习和无监督学习之间的是半监督学习(Semi-supervised Learning)
半监督学习的训练数据一部分有标记,另一部分没有标记,而没有标记数据的数量常常远大于有标记数据的数量。
半监督学习的基本规律是:数据的分布必然不是完全随机的,通过结合有标记数据的局部特征以及大量没有标记数据的整体分布,可以得到比较好的分类结果。
强化学习
强化学习(Reinforcement Learning)是解决计算机从感知到决策控制的问题,从而实现通用人工智能。
强化学习是以目标为导向的。它的训练是从一张白纸的状态开始,经由许多个步骤来实现某一维度上的目标最大化。简单的来说,就是在训练过程中,不断地去尝试,错误就惩罚,正确就奖励,由此训练得到的模型在各个状态环境中都最好。
对于强化学习来说,它虽然没有标记,但有一个延迟奖励与训练相关,通过学习过程中的激励函数获得某种从状态到行动的映射。
强化学习强调如何基于环境而行动,以取得最大化的预期利益。
强化学习一般适用于游戏、下棋等需要连续决策的领域。
深度学习简介
神经元
神经元通常是由细胞核、树突、轴突、突触等组成。一个神经元有多个树突用来接收信息,一个轴突用来传送信息。

1943年,心理学家Warren McCulloch和数学家Walter Pits发明了神经元模型。可以看到下图的左边有许多的输入,类似于神经元的树突,经过一个细胞核的处理,也就是下图中加权求和的部分,再通过激活函数,最后得到一个输出。

神经网络
如果我们把多个单一的神经元组合在一起,就会有一些神经元的输出作为另一些神经元的输入,这样就构成了神经网络。

输入层和输出层的神经元数量是固定的,而中间隐藏层到底需要几层,每一层需要多少个神经元的个数是可以自由调整的。
激活函数
Sigmoid激活函数
S型(Sigmoid)激活函数可以把它的输入转变成介于0-1之间的值。

ReLU激活函数
修正线性单元激活函数(ReLU),它的效果通常来讲比Sigmoid好一些,而且非常容易计算。

深度神经网络
神经网络算法的核心就是计算、连接、评估、纠错和训练
深度学习的深度就在于通过不断增加中间隐藏层数和神经元数量,让神经网络变得又宽又深,让系统运行大量数据,训练它。

卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是深度学习中最重要的概念之一。

生成卷积核 >> 执行卷积算法 >> 池化 >> 卷积 >> 池化 >> 全连接
我自己的理解:图像识别中比较常见,根据输入图片中的特征点,根据算法生成卷积核,通过卷积算法进行矩阵计算,然后池化缩小范围,最后全连接转化为一个数组。
各类卷积网络
- AlexNet
- VGG Net
- Google Net
深度学习框架

Theano
Theano是一个比较低层的库,适合数值计算优化。支持自动的函数梯度计算,带有Python接口并集成了Numpy,可以说Theano是Python的一个数值计算库。但它也有些缺陷,它不支持多GPU和水平扩展。
Caffe
Caffe的全称是“Convolutional Architecture For Feature Extraction”,意为“用于特征提取的卷积架构”,它的设计初衷是为了计算机视觉。但它也存在灵活性不足的问题,为模型做调整常常需要用到C++和CUDA。
在2017年4月Facebook发布了Caffe2,Caffe2可以看作是Caffe更细粒度的重构,在实用的基础上,增加了扩展性和灵活性。
PyTorch
Torch是一个非主流的深度学习框架,它的开发语言是基于20世纪90年代诞生于巴西的Lua,而现在主流的机器学习界所采用的语言,基本上都是Python,因此,用Lua显得有些“非主流”。
Facebook的人工智能研究所使用的框架就是Torch。Torch非常适用于卷积神经网络,它的灵活度更高,因为它是命令式的,所以支持动态图模型。
大多数的深度学习框架都是支持静态图模型的,也就是说,它要先把模型定义好,然后再进行运行计算,而Torch的灵活度更高,它可以像交互式的命令一样,边运行边更改,在运行的过程中去定义它的图模型,这样叫做动态图模型。
2017年初,Facebook在Torch的基础上,针对Python语言发布了一个全新的机器学习工具包PyTorch。PyTorch可以说是Torch的Python版,增加了很多新的特性。
2018年4月,Facebook宣布Caffe2将正式将代码并入PyTorch。
MXNet
MXNet是亚马逊AWS选择支持的深度学习框架。
MXNet尝试将两种模式无缝的结合起来:在命令式编程上,MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。这样,用户可以自由地混合它们来快速实现自己的想法,也就是说,它结合了静态定义计算图和动态定义计算图的优势。
MXNet支持C++、Python、R、Julia、Go语言,但是它的学习难度较高。
CNTK
Microsoft 认知工具包(Cognitive Toolkit) 之前被大家所知的缩略是CNTK。
2016年,微软宣布已经在GitHub上向外部开发人员开源其人工智能工具包CNTK(Computational Network Toolkit)。
CNTK工具包中的语音和图像识别速度比较快,而且它还具有着更为强大的可扩展性——开发者可以用多台计算机实现GPU的扩展,从而能够更加灵活地应对大规模的实验。对于广大Windows系列的开发者来说,它支持C#是一个非常好的福音。
Keras
Keras是一个非常高层的库,可以工作在Theano、TensorFlow和CNTK之上。
Keras强调极简主义——你只需要几行代码就能构建一个神经网络。它是为支持快速实验而生,能够把你的idea迅速转换为结果。它的句法相当明。
DL4J
DL4J(Deep Learning For Java)是基于JVM、聚焦行业应用且提供商业支持的分布式深度学习框架,其宗旨是在合理的时间内解决各类涉及大量数据的问题。
它对Java的支持就是它最大的特点。它可以与Hadoop和Spark集成,可使用任意数量的GPU或CPU运行。这就为广大的Java从业人员提供了一个好的深度学习工具。
Chainer
Chainer是一个专门为高效研究和开发深度学习算法而设计的开源框架。它也是基于Python的独立的深度学习框架。
Chainer在训练时,“实时”构建计算图,“边运行边定义”的方法使构建深度学习网络变得灵活简单,也就是说,它支持动态图定义。
这种方法可以让用户在每次迭代时或者说对每个样本都可以根据条件更改计算图,同时也很容易使用标准调试器和分析器来调试和重构基于Chainer的代码。
Paddle
Paddle Paddle是百度旗下深度学习开源平台。
TensorFlow
“A machine learning platform for everyone to solve real problems”,即对每个人来解决现实问题的机器平台,这也是TensorFlow存在的宗旨。
它不仅在上层支持神经网络,它还很全面的支持其他机器学习的算法,比如K-Means、决策树、支持向量机等等。它对语言的支持也很多,比如Python、C++、Java等等。此外,在硬件层面,它也可以支持CPU、GPU、TPU、Mobile(移动平台上)等等。

此外,TensorFlow提供了不同层次的接口,从低层到高层。越低层越灵活、越容易去控制,而越高层越容易使用。最低层的就是TensorFlow直接提供的低层接口。