
二叉树的深度*
未解决的问题
为什么DFS运行效率高??
二叉树深度
我们定义从根节点开始
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
1 | 3 |
返回它的最大深度 3 。
解决
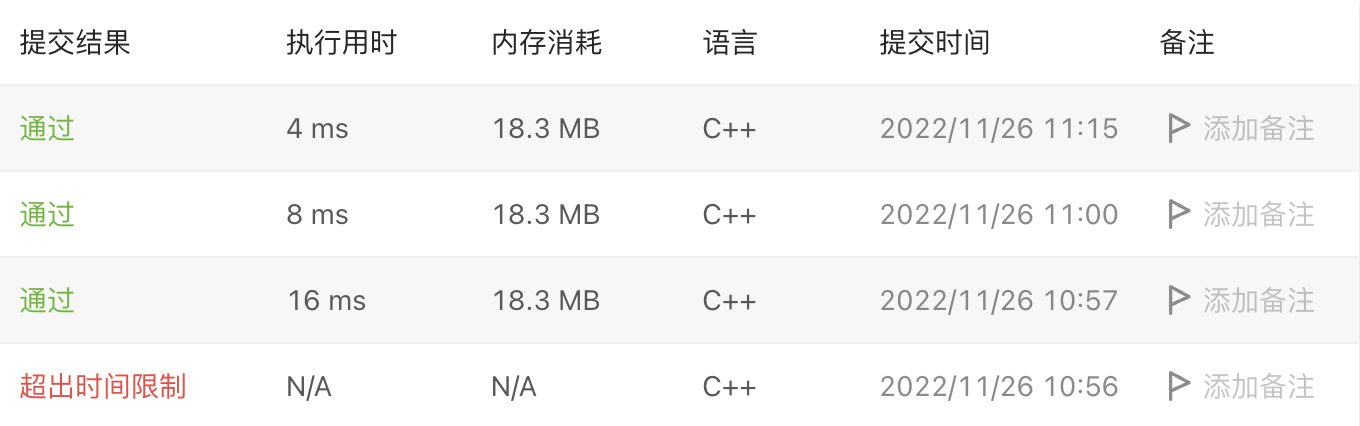
这是我的提交记录
通过递归遍历获取深度
分别递归每一个子树,返回当前的深度。然后进行对比
代码1
1 | int maxDepth(TreeNode* root) { |
此代码提交超出时间限制
我认为主要原因是因为返回值同时调用多个函数进行对比,函数重复调用浪费时间。我们应该把函数结果记录下来直接进行对比,而不是在反复调用函数进行对比
代码2
1 | int maxDepth(TreeNode* root) { |
执行时间16ms
添加两个变量r和l分别记录左子树和右子树的深度,返回最大深度+1获取当前树深度。
较少了代码1的重复调用带来的时间浪费。
代码3
1 | int maxDepth(TreeNode* root) { |
执行时间8ms
此代码直接将函数返回结果进行对比,类似代码1。代码1使用三元运算符重复调用多次函数造成大量时间浪费。
DFS
定义全局变量,分别表示当前深度和最大深度。
每次向下遍历,深度+1,函数执行完成后,返回上层深度-1。
1 | int deepth=0; |
执行时间4ms
每向下递归一层,深度+1,当递归到没有子叶时,返回m的最大值。
